Se implementaron cinco arquitecturas diferentes de redes neuronales convolucionales
(CNN) para la clasificación de personajes:
Arquitectura
-
Capas Conv2D
4
-
Capas BatchNormalization
4
-
Capas MaxPooling2D
4
-
Capas Dense
2
-
Capas Dropout
1
Parámetros
Parámetros totales
2,511,535
Parámetros entrenables
2,510,575 (99.96%)
Parámetros no entrenables
960 (0.04%)
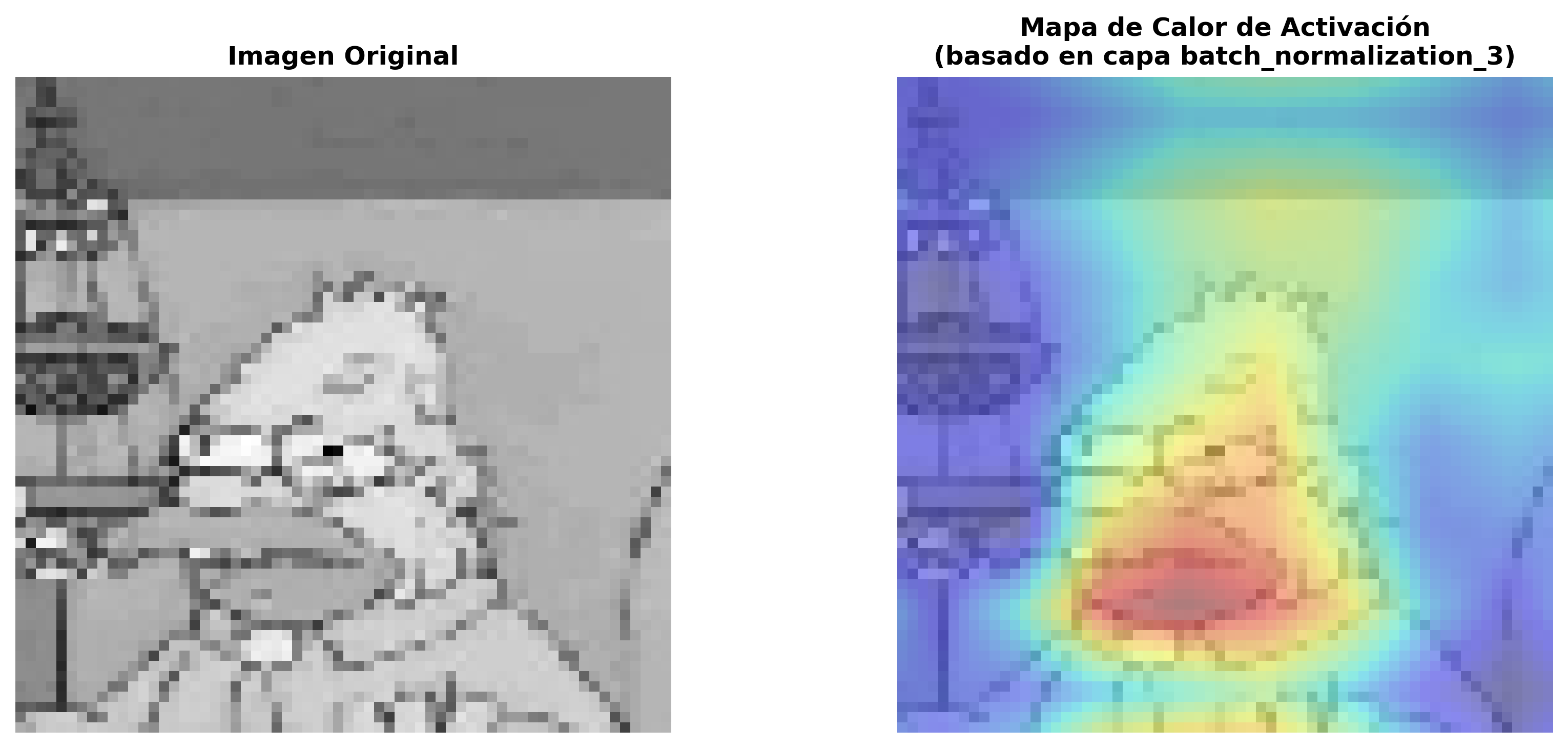
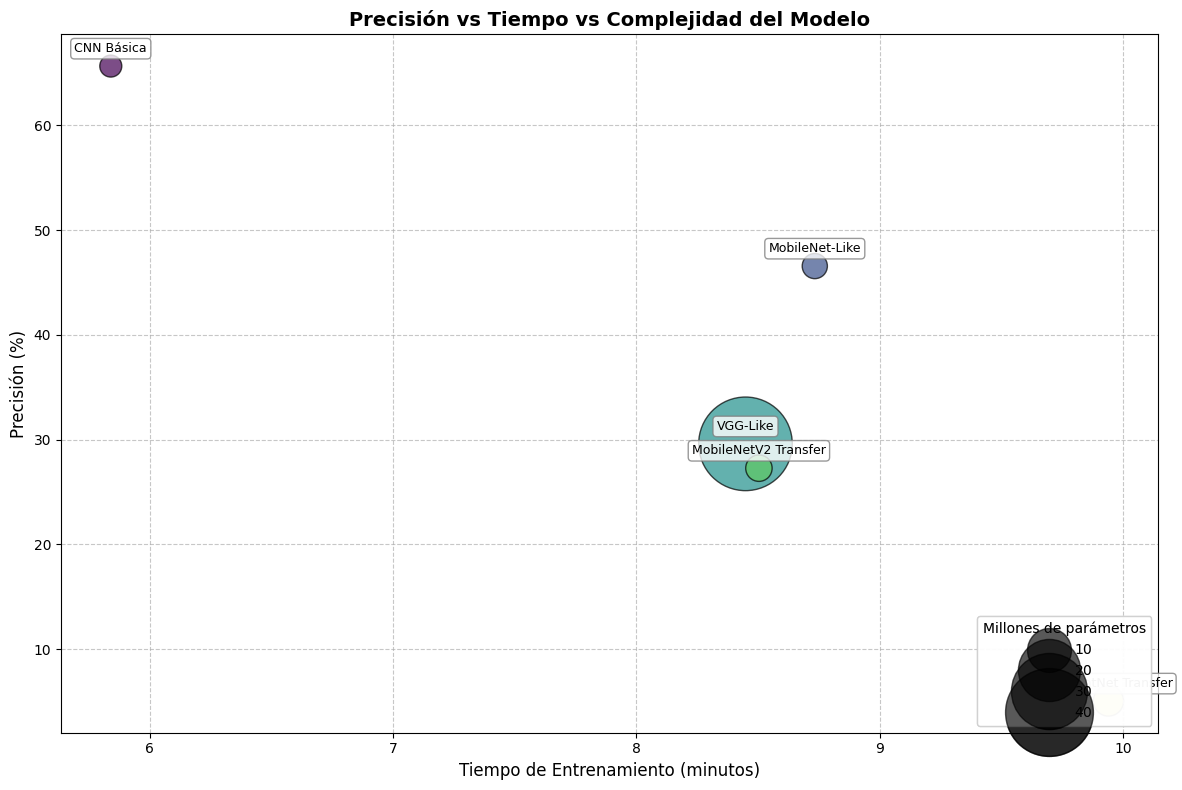
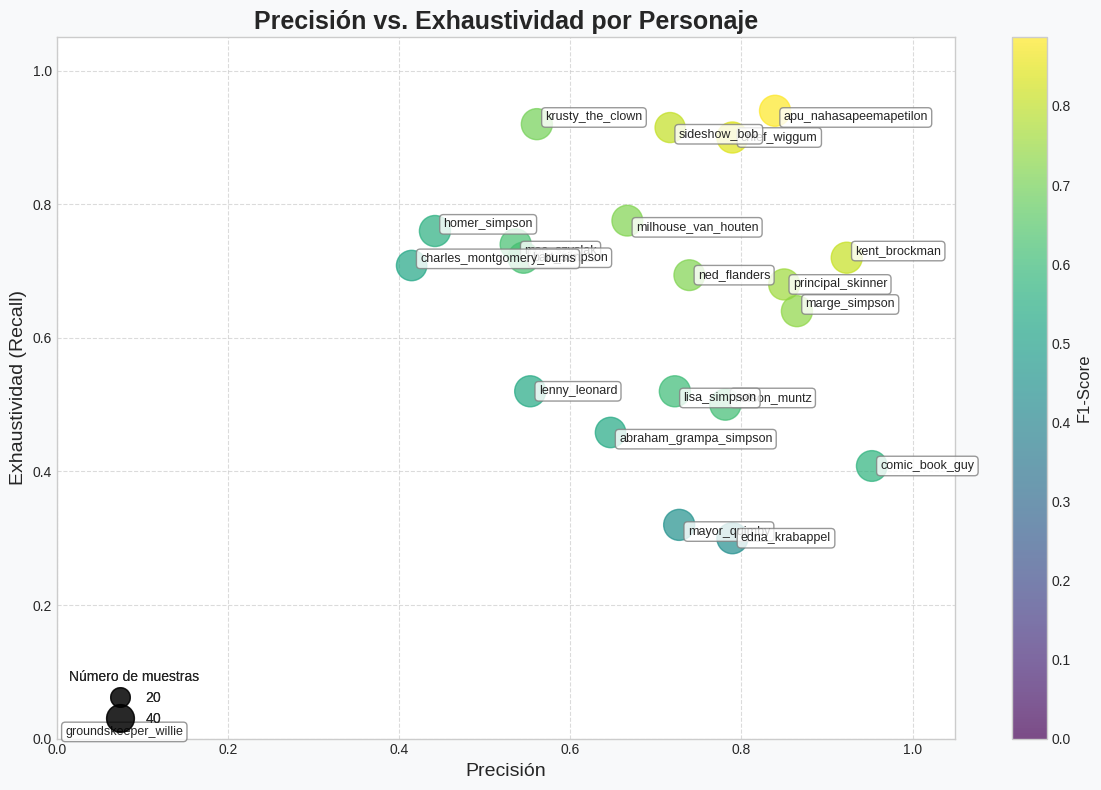
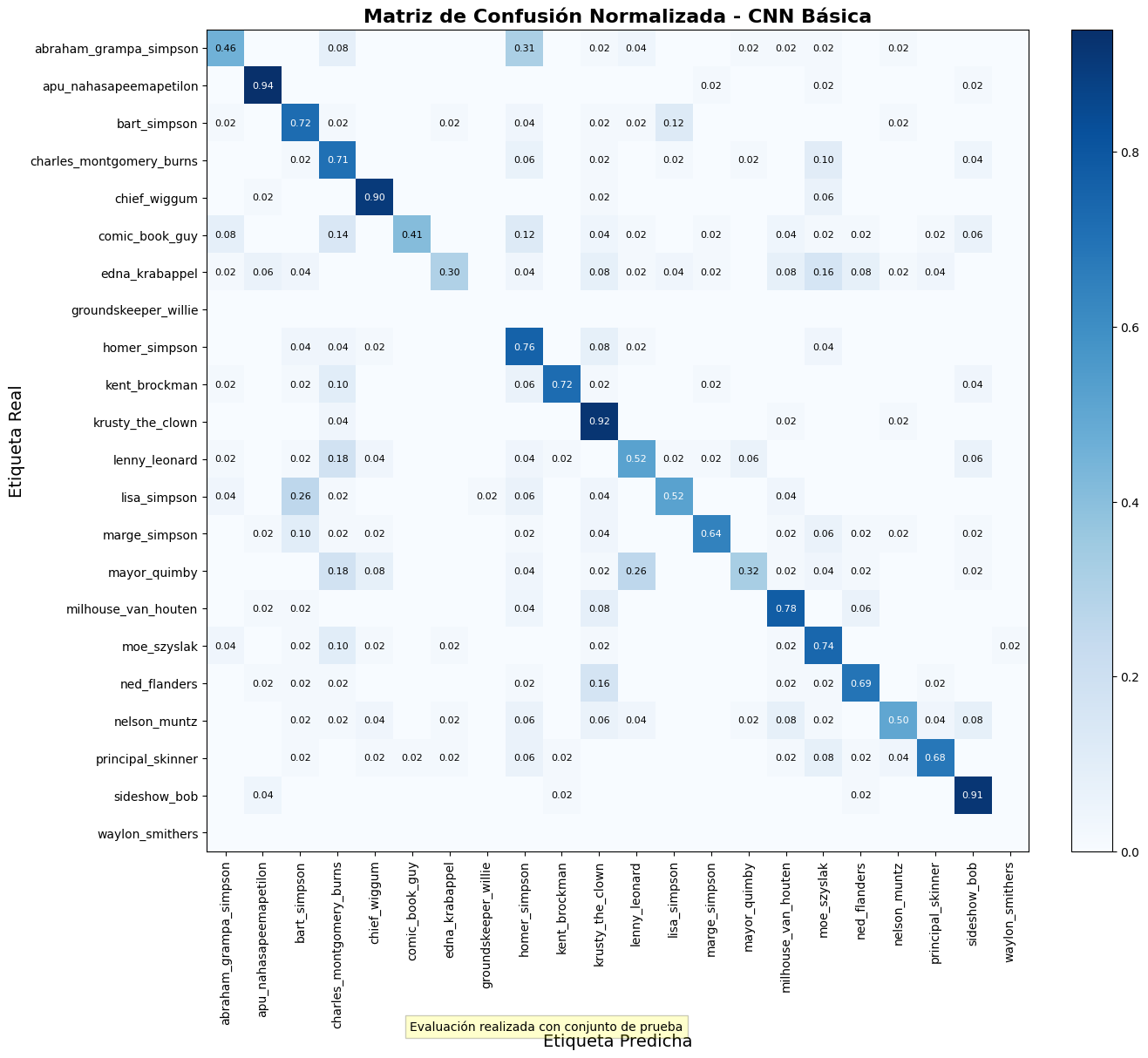
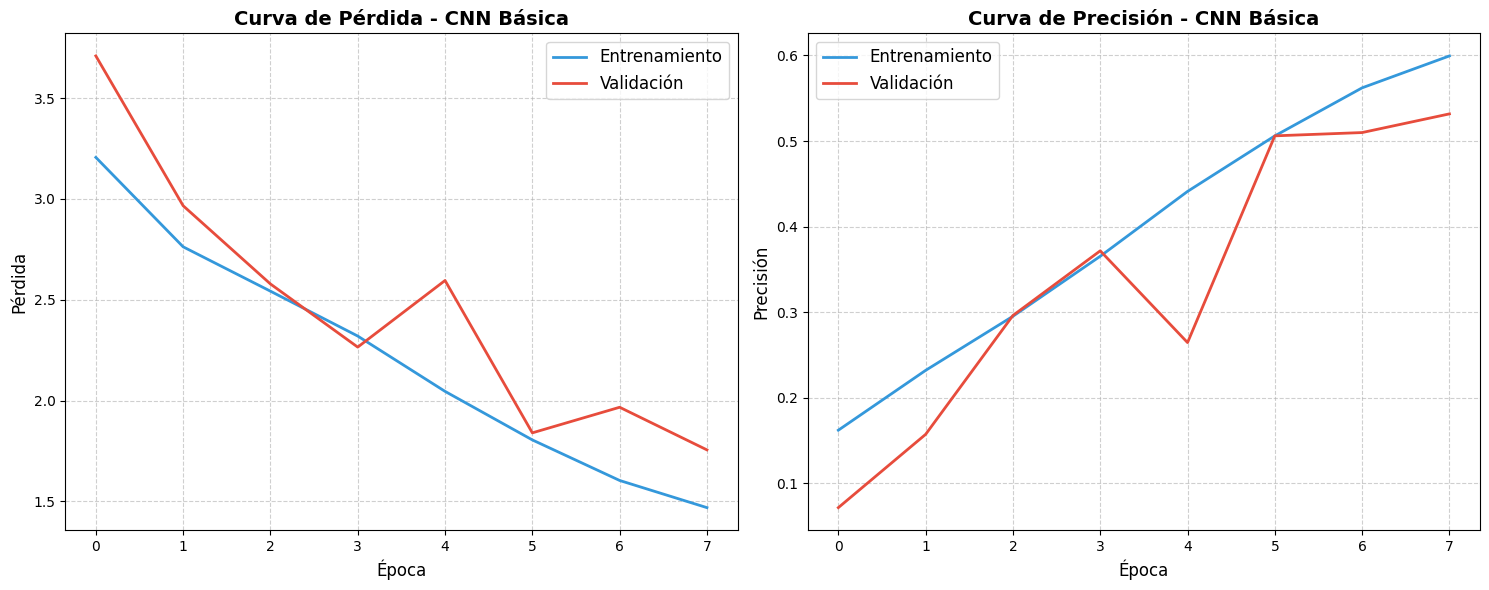
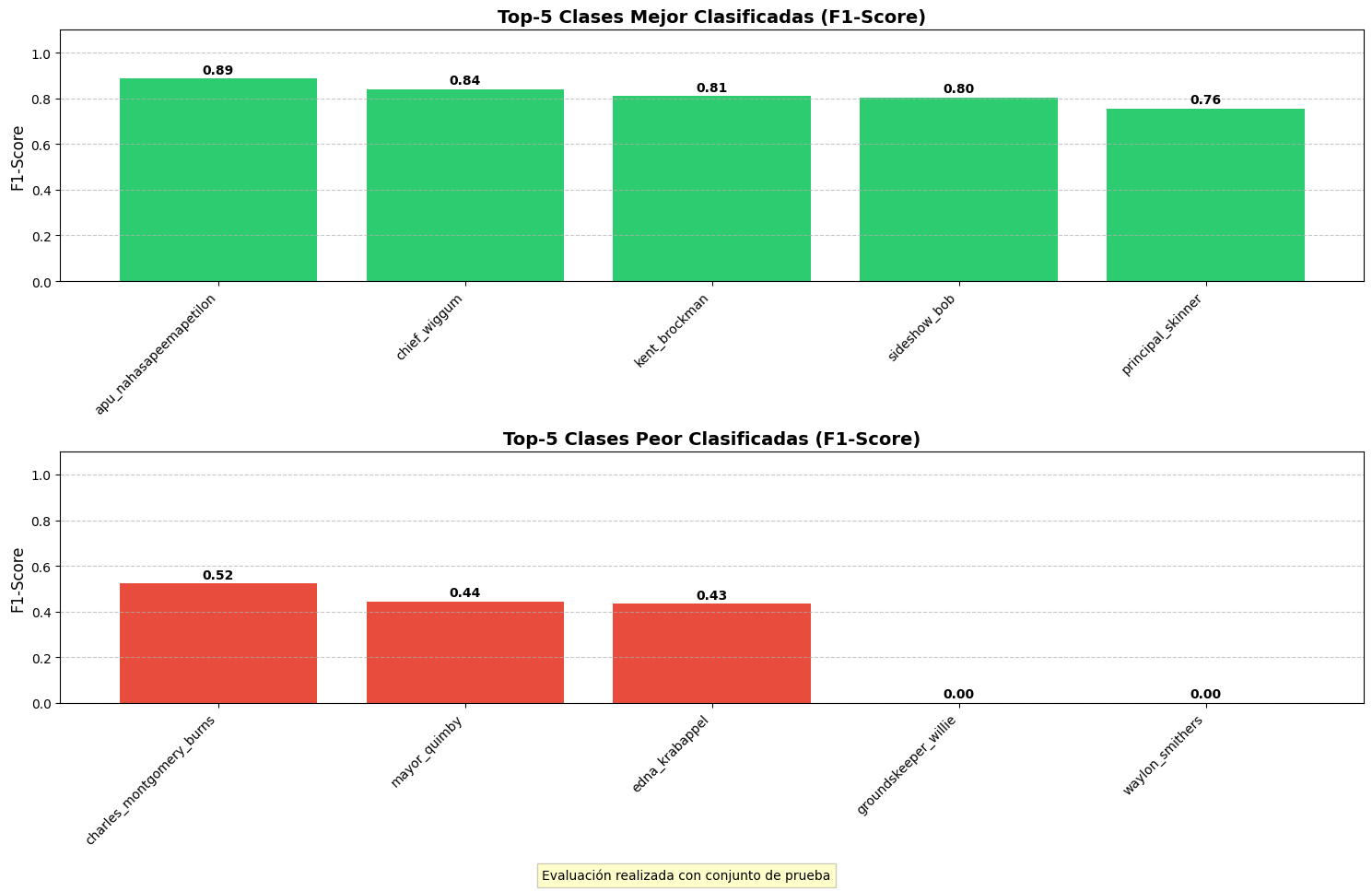
Este modelo demostró ser el más efectivo
para la tarea de clasificación, con una precisión de test del 63.13%.
Arquitectura
-
Capas Conv2D
10
-
Capas BatchNormalization
10
-
Capas MaxPooling2D
4
-
Capas Dense
3
-
Capas Dropout
2
Parámetros
Parámetros totales
45,446,895
Parámetros entrenables
45,441,519 (99.99%)
Parámetros no entrenables
5,376 (0.01%)
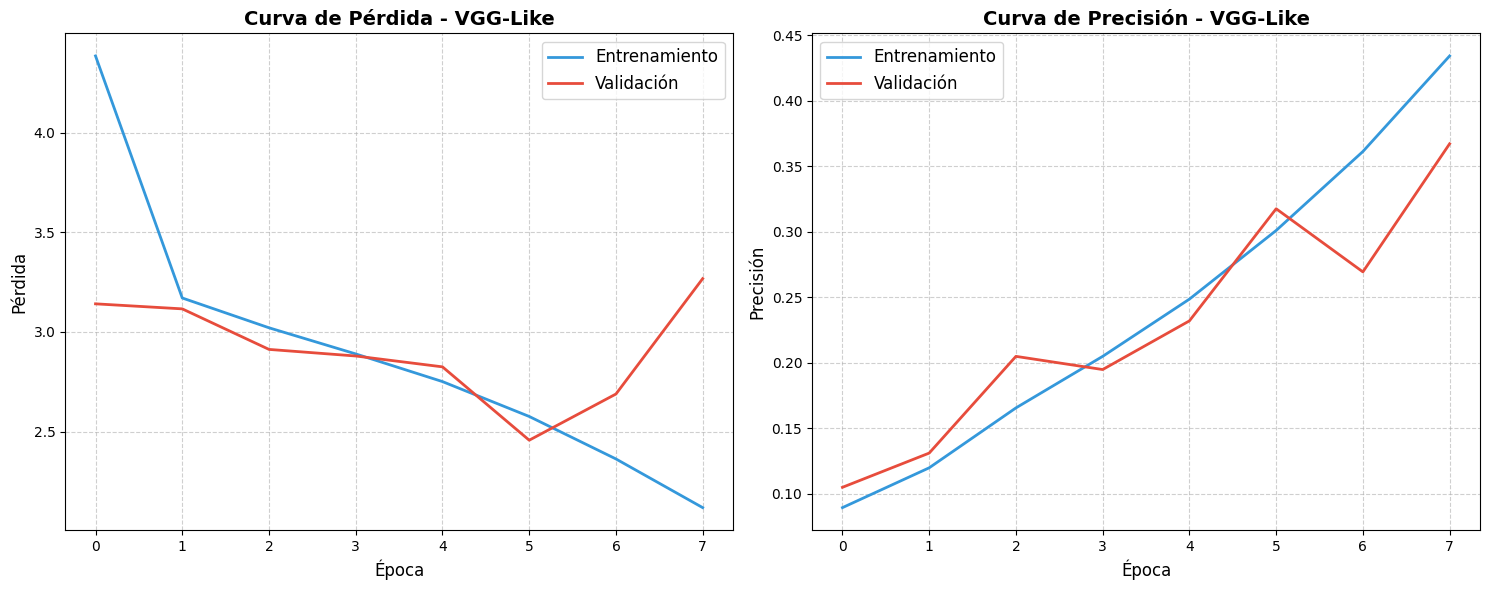
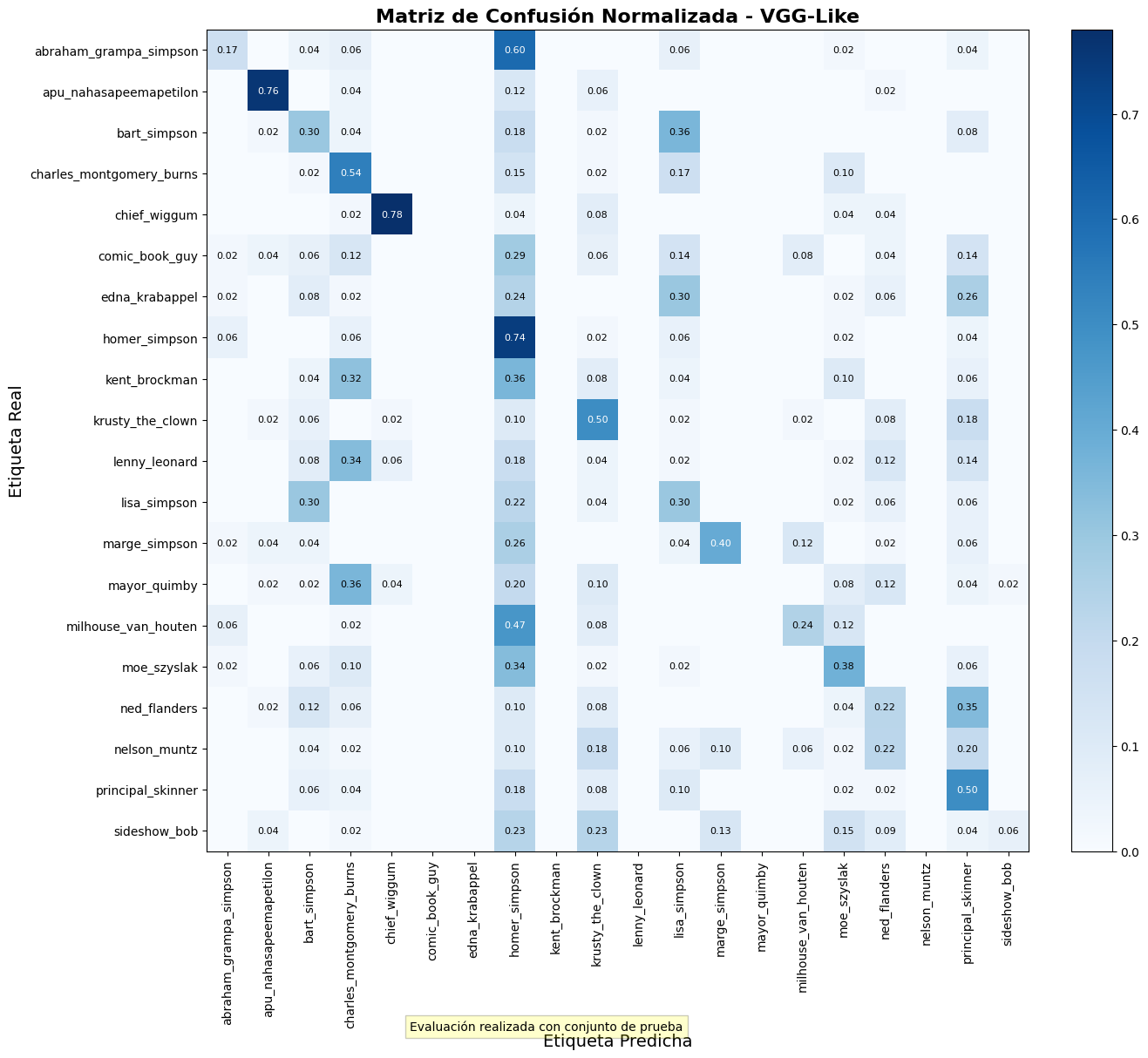
Este modelo, a pesar de tener muchos más
parámetros, logró una precisión de test del 39.09%, significativamente menor que
la CNN Básica.
Arquitectura
-
Capas Conv2D
14
-
Capas DepthwiseConv2D
13
-
Capas BatchNormalization
27
-
GlobalAveragePooling2D
1
-
Capas Dense
1
Parámetros
Parámetros totales
3,287,407
Parámetros entrenables
3,265,519 (99.3%)
Parámetros no entrenables
21,888 (0.7%)
Este modelo alcanzó una precisión de
test del 47.27%, siendo el segundo mejor modelo entre los evaluados.
Arquitectura
-
Modelo base MobileNetV2
1
-
Conv2D (conversión a 3 canales)
1
-
GlobalAveragePooling2D
1
-
Capas Dense
2
-
Capas BatchNormalization
1
-
Capas Dropout
1
Parámetros
Parámetros totales
3,622,005
Parámetros entrenables
1,361,973 (37.6%)
Parámetros no entrenables
2,260,032 (62.4%)
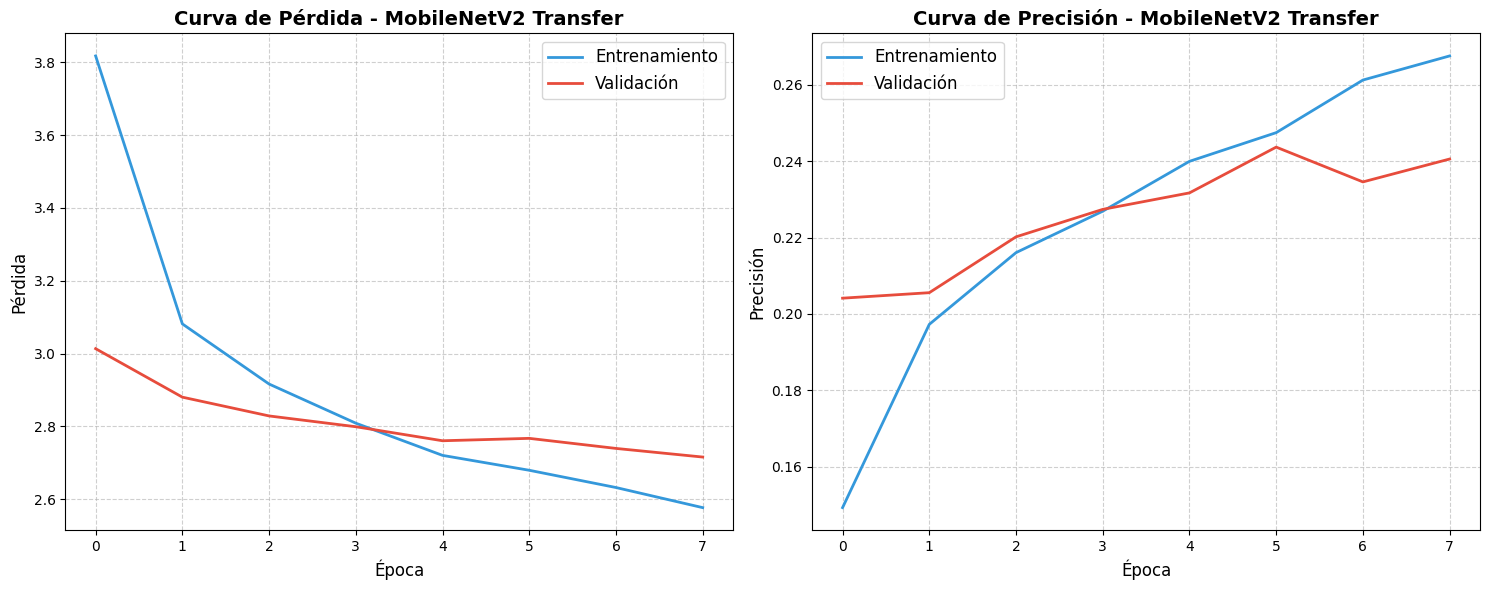
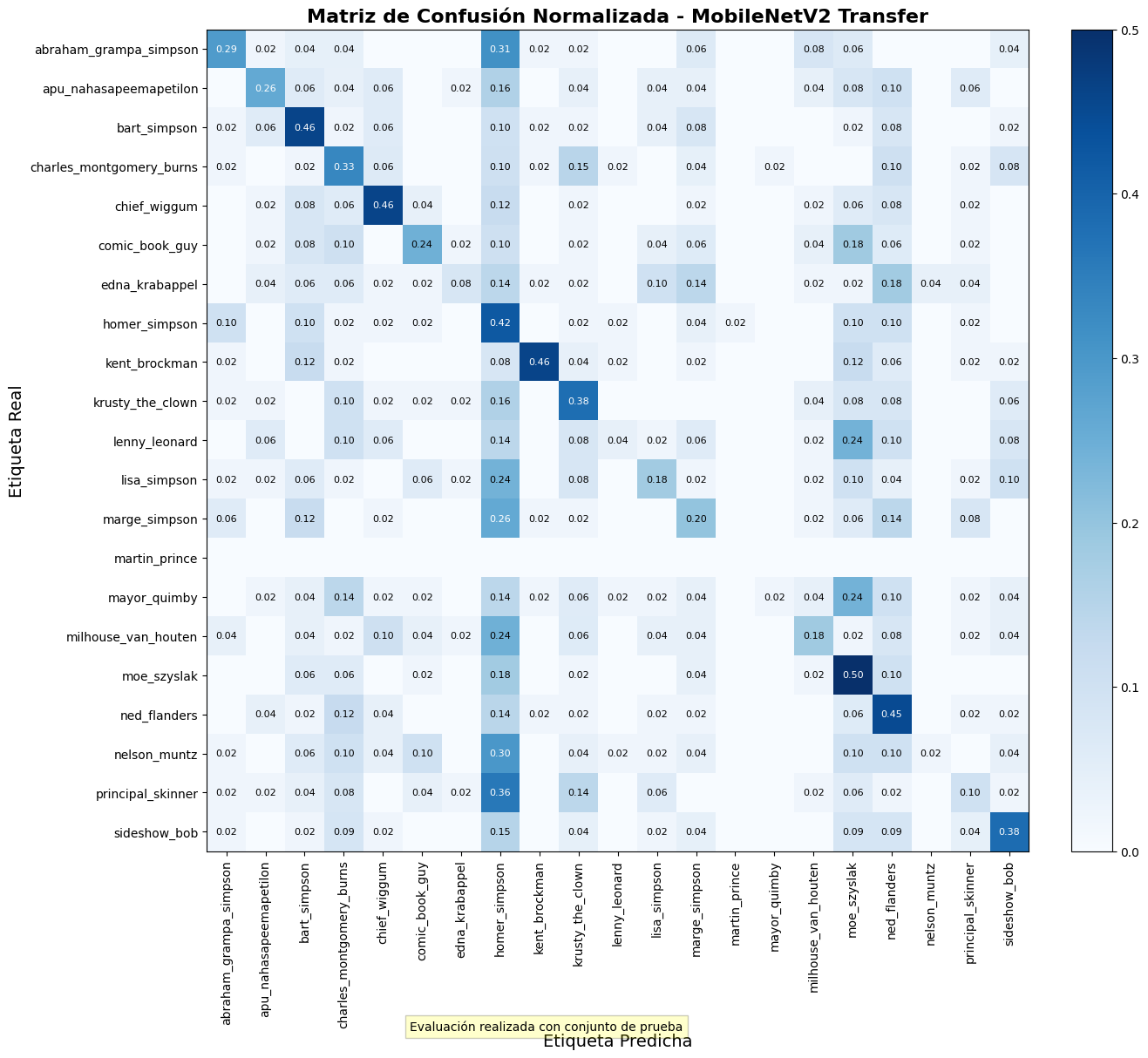
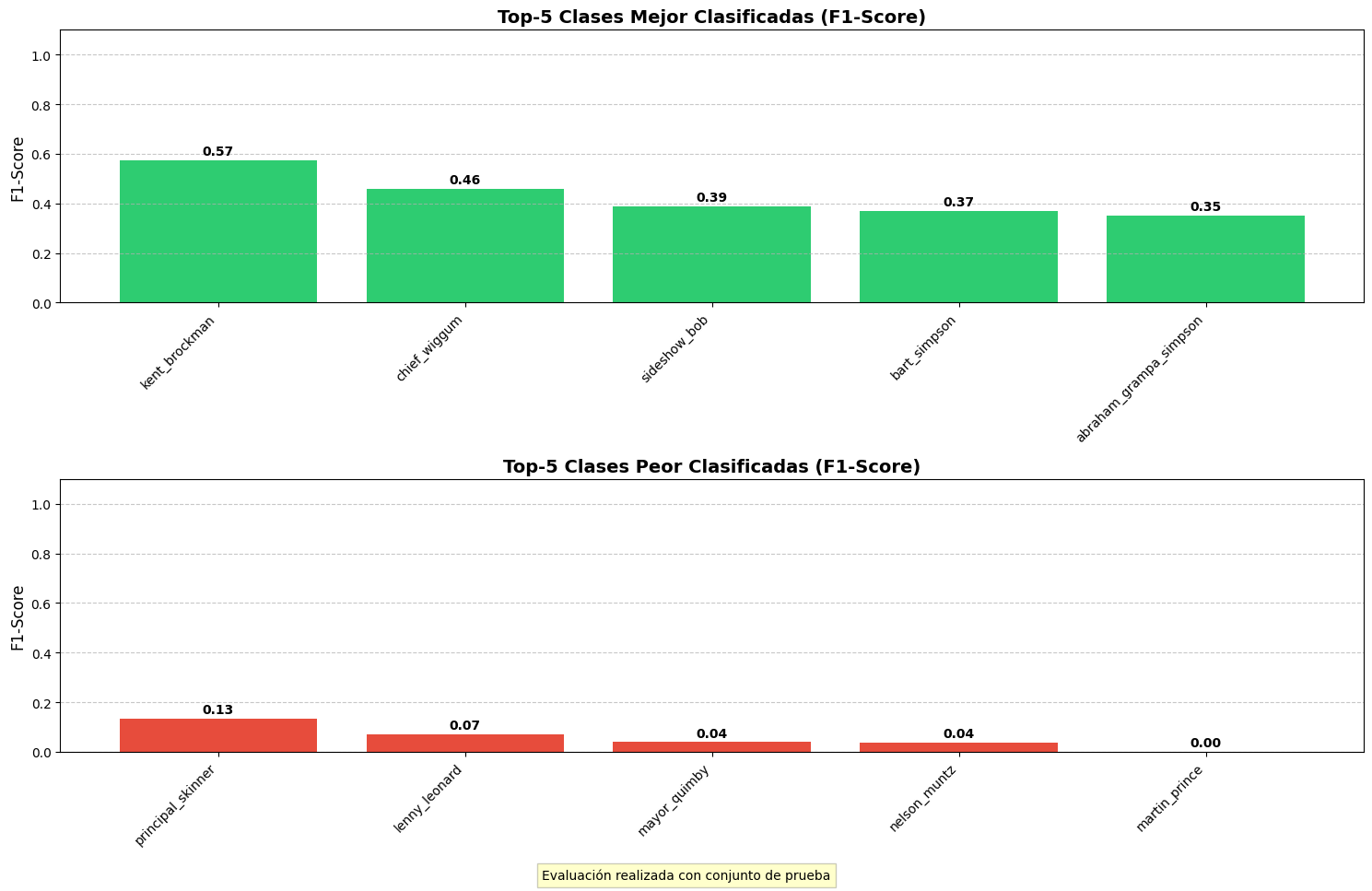
Este modelo de transfer learning alcanzó
una precisión de test del 37.47%.
Arquitectura
-
Modelo base EfficientNetB0
1
-
Conv2D (conversión a 3 canales)
1
-
GlobalAveragePooling2D
1
-
Capas Dense
2
-
Capas BatchNormalization
2
-
Capas Dropout
2
Parámetros
Parámetros totales
4,736,728
Parámetros entrenables
683,573 (14.4%)
Parámetros no entrenables
4,053,155 (85.6%)
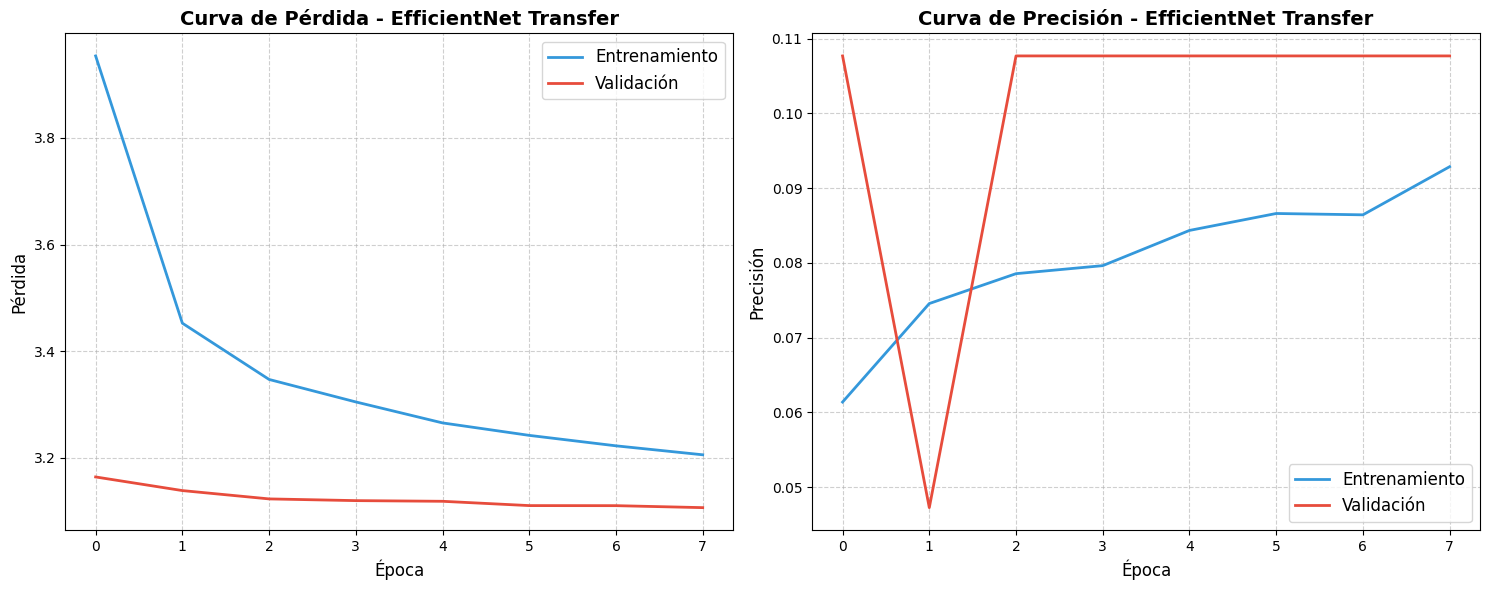
Este modelo obtuvo el peor
rendimiento entre todos los evaluados, con una precisión de test de solo 5.05%.
Las arquitecturas evaluadas presentan diferentes enfoques para la clasificación de
imágenes:
- CNN Básica: Arquitectura simple pero efectiva, con un buen balance
entre complejidad y rendimiento.
- VGG-Like: Modelo más profundo con muchos más parámetros, pero que
no se traduce en mejor rendimiento para este conjunto de datos específico.
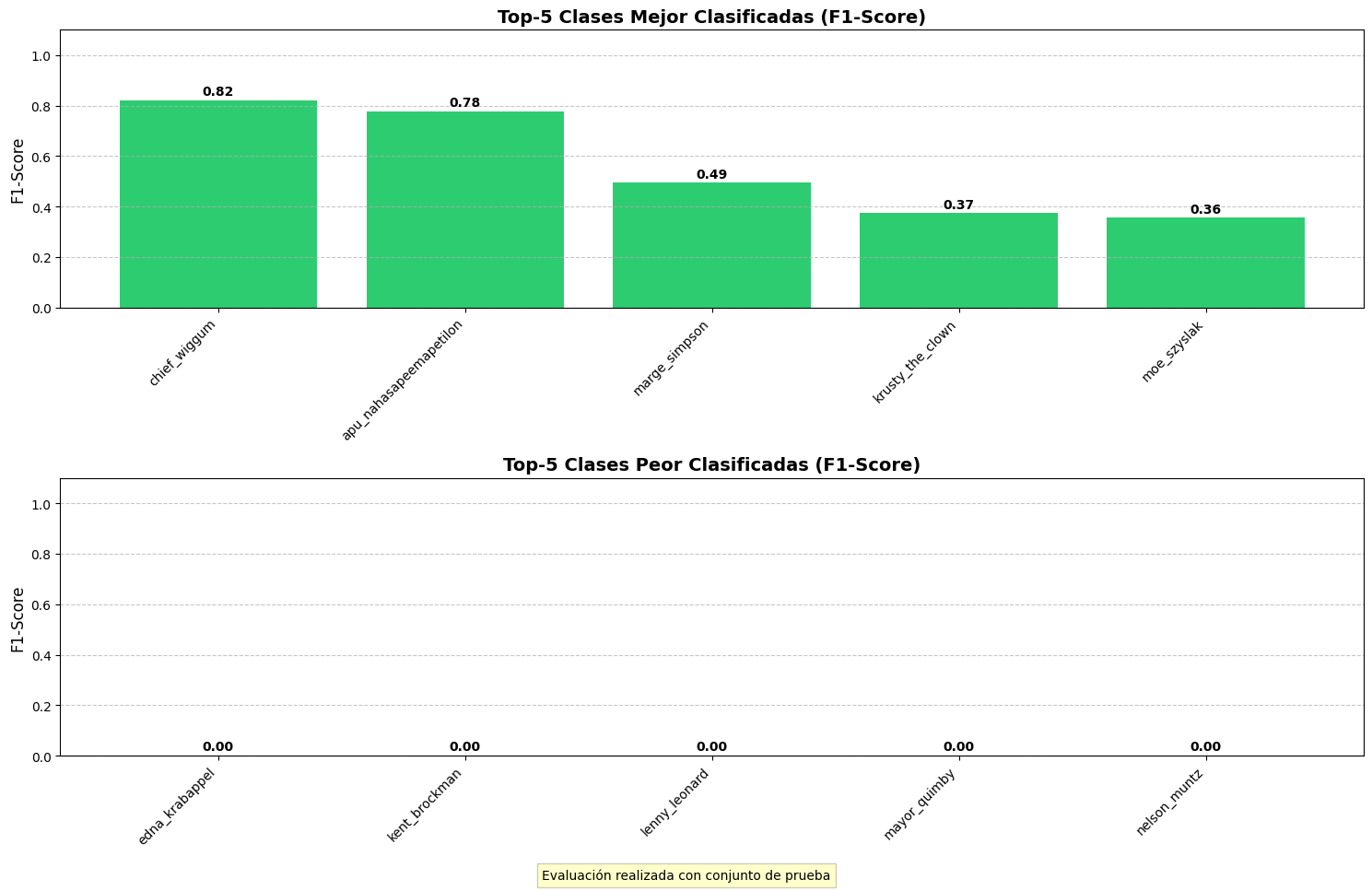
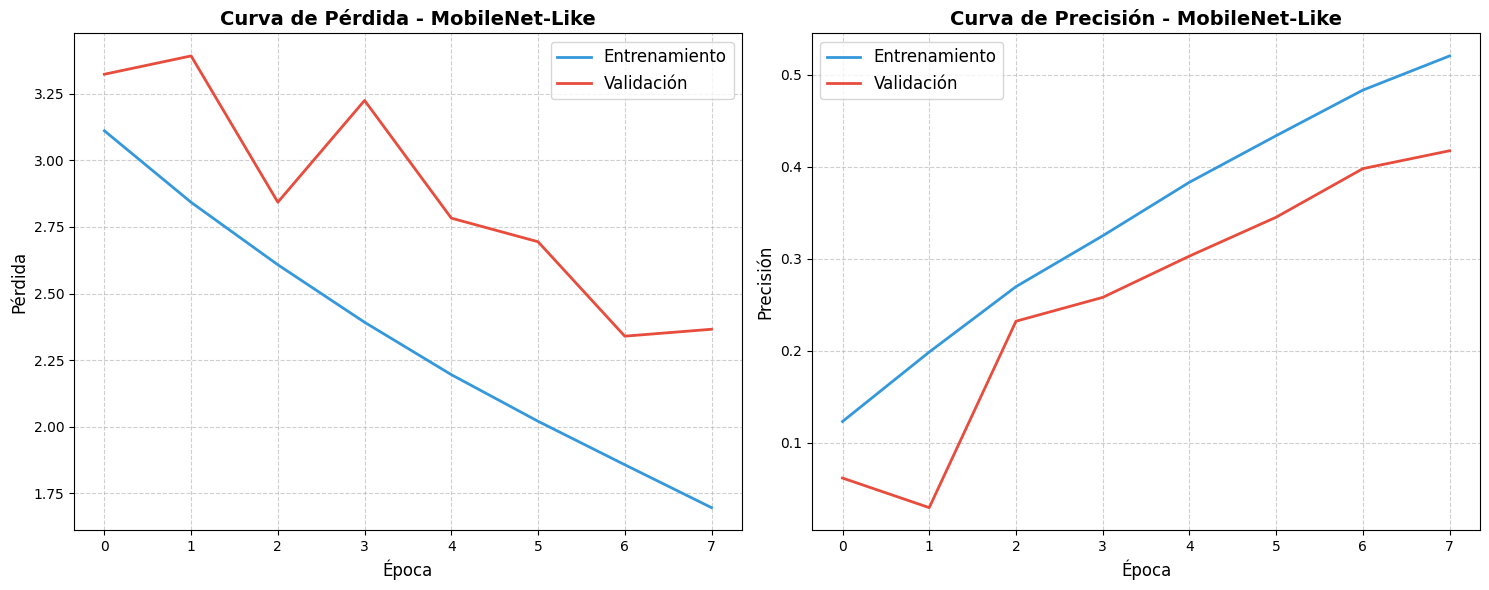
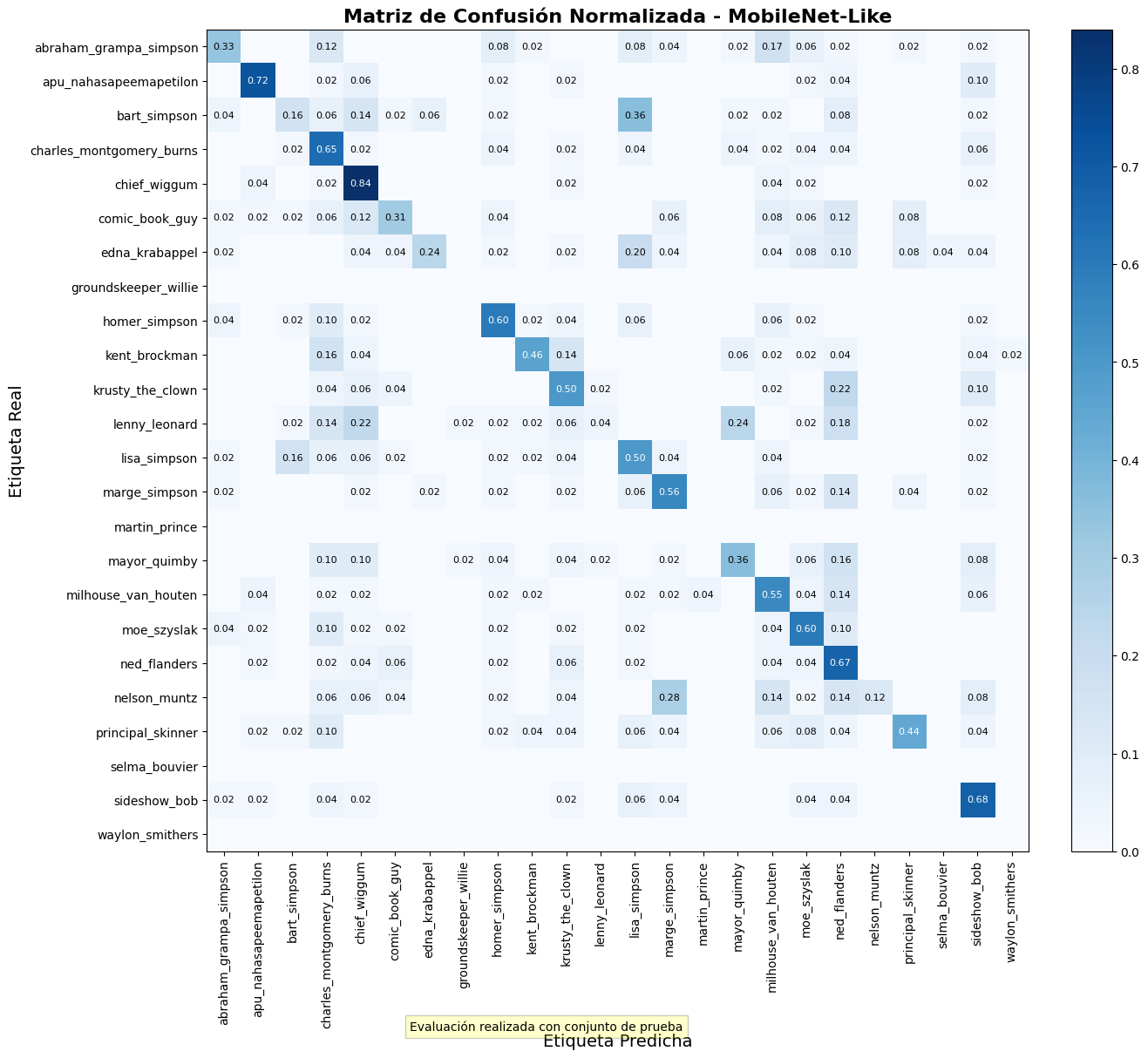
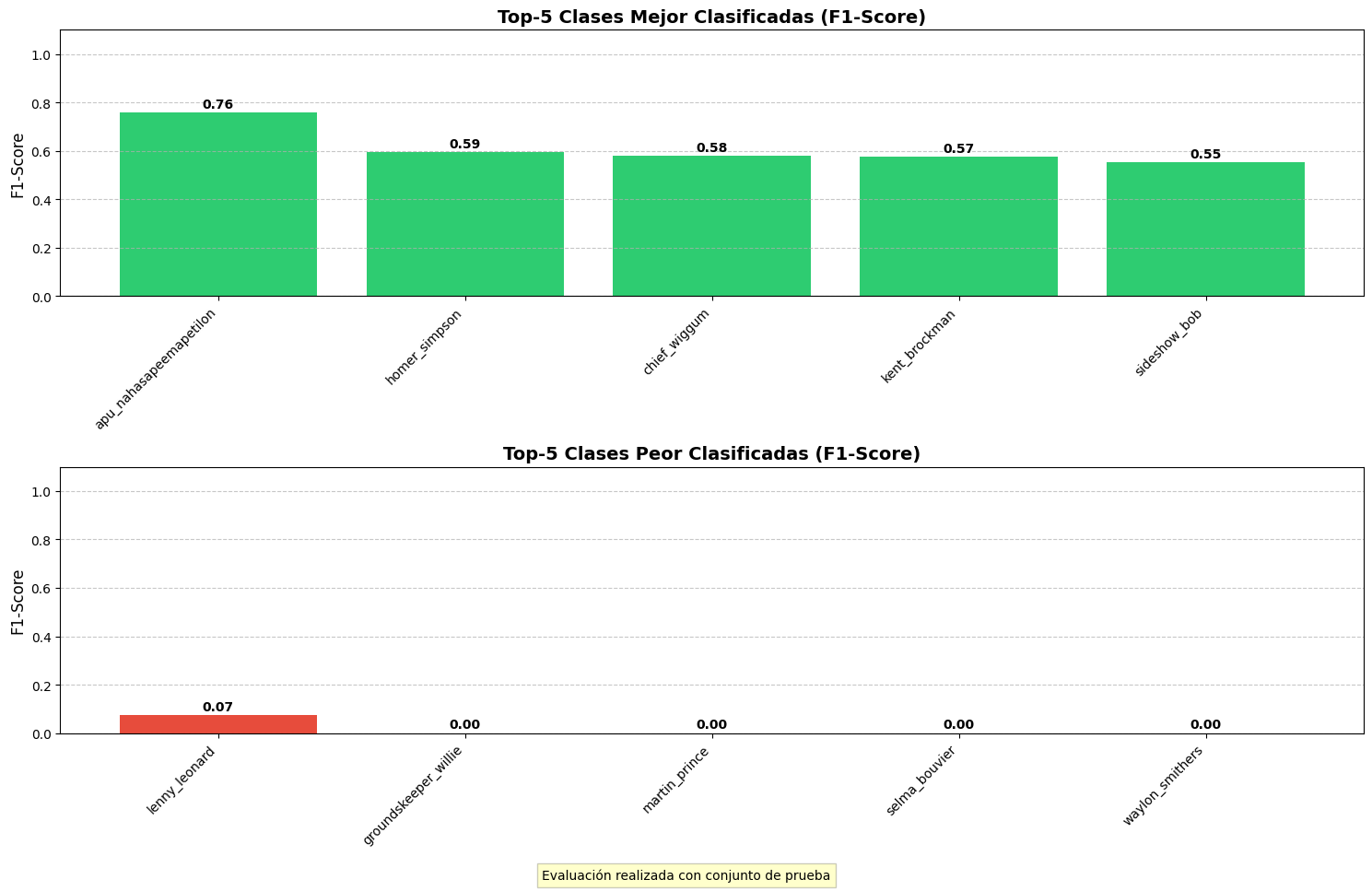
- MobileNet-Like: Arquitectura que utiliza convoluciones separables
en profundidad para reducir el número de parámetros manteniendo un rendimiento
aceptable.
- Transfer Learning: Los modelos pre-entrenados (MobileNetV2 y
EfficientNet) no lograron superar a los modelos entrenados desde cero, posiblemente
debido a la diferencia entre las imágenes naturales de ImageNet y los dibujos
animados de Los Simpson.
Arquitecturas CNN para clasificación de imágenes
Las redes neuronales convolucionales (CNN) son particularmente efectivas para la
clasificación de imágenes debido a su capacidad para detectar patrones espaciales. Las
arquitecturas evaluadas en este proyecto varían en su complejidad y enfoque.
Mientras que las redes más profundas como VGG suelen funcionar bien en conjuntos de datos
grandes y complejos, para tareas específicas como la clasificación de personajes animados,
una arquitectura más simple y ajustada puede ofrecer mejores resultados con menos recursos
computacionales.