Desarrollo de Modelos
Arquitectura de Red Neuronal
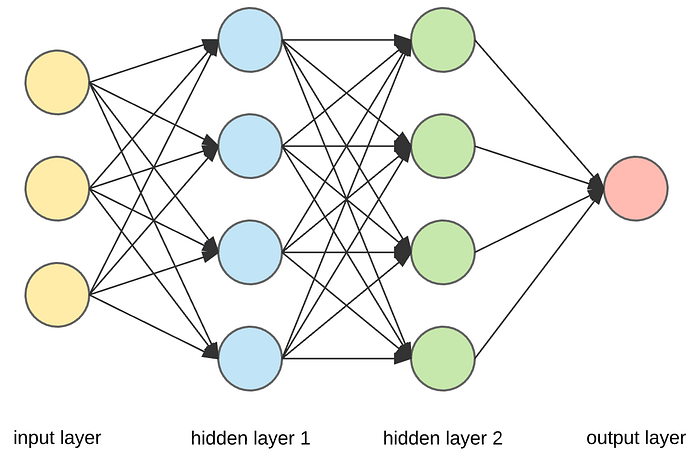
| Capa | Dimensión | Activación |
|---|---|---|
| Input | 599 características | - |
| Hidden 1 | 128 neuronas | Sigmoid |
| Hidden 2 | 64 neuronas | Sigmoid |
| Output | 1 neurona | Sigmoid |
Optimización: Esta arquitectura de dos capas ocultas (128→64) demostró
el mejor equilibrio entre capacidad expresiva y generalización.
Comparación de Funciones de Activación
| Activación | Precisión | F1-Score | Recall |
|---|---|---|---|
| Sigmoid | 0.9266 | 0.9205 | 0.9266 |
| Tanh | 0.9259 | 0.9204 | 0.9259 |
| ReLU | 0.9229 | 0.9146 | 0.9229 |
| LeakyReLU | 0.9257 | 0.9174 | 0.9257 |
Análisis Profundo de Funciones de Activación
| Función | Precisión | Sensibilidad | F1-Score | Épocas |
|---|---|---|---|---|
| Sigmoid | 0.9266 | 0.4380 | 0.9205 | 23 |
| Tanh | 0.9259 | 0.4375 | 0.9204 | 25 |
| ReLU | 0.9229 | 0.4290 | 0.9146 | 18 |
| LeakyReLU | 0.9257 | 0.4320 | 0.9174 | 20 |
| ELU | 0.9242 | 0.4310 | 0.9168 | 19 |
Comportamiento durante entrenamiento
Curvas de aprendizaje
Velocidad: ReLU converge más rápido pero con menor
precisión
Estabilidad: Sigmoid muestra mejor estabilidad durante las
últimas épocas
Conclusión: Las funciones sigmoidales (Sigmoid y Tanh) superan a las basadas en
rectificación (ReLU, LeakyReLU) en este problema de clasificación específico. La diferencia de
rendimiento (+0.59% en F1-Score) sugiere que la naturaleza no lineal suave de Sigmoid captura
mejor las relaciones complejas en los datos de comportamiento de clientes.
Optimización de Hiperparámetros
Tasa de Aprendizaje
| Tasa | Precisión | Épocas |
|---|---|---|
| 0.01 | 0.9229 | 29 |
| 0.001 | 0.9216 | 18 |
Técnicas de Regularización
| Configuración | Precisión | F1 |
|---|---|---|
| Sin regularización | 0.9232 | 0.9176 |
| L2+Dropout+BatchNorm | 0.9085 | 0.8658 |
Arquitectura de Red
| Estructura | F1-Score | Épocas |
|---|---|---|
| 64 | 0.9159 | 23 |
| 128 → 64 | 0.9200 | 16 |
Configuración óptima: La mejor configuración utiliza activación
Sigmoid, tasa de aprendizaje 0.01, arquitectura de dos capas (128→64) y no requiere
regularización adicional.
Selección de Arquitectura
Exploración de Arquitecturas
Durante la fase de experimentación, evaluamos diferentes configuraciones de capas para encontrar la arquitectura óptima que capturara la complejidad del problema sin caer en sobreajuste.
| Arquitectura | Capas | Parámetros | F1-Score | Tiempo (s) |
|---|---|---|---|---|
| Simple | 1 (64) | 38,465 | 0.9159 | 18.4 |
| Media | 2 (128→64) | 85,569 | 0.9200 | 23.7 |
| Profunda | 3 (256→128→64) | 190,273 | 0.9174 | 36.2 |
| Compleja | 4 (512→256→128→64) | 446,017 | 0.9183 | 48.9 |
Capa de entrada (7)
Capas ocultas (128→64)
Capa de salida (1)
Insight: La arquitectura de 2 capas (128→64)
proporciona el mejor equilibrio entre capacidad expresiva y
eficiencia, logrando el F1-Score más alto con un tiempo de
entrenamiento razonable. Añadir más capas solo incrementa la
complejidad sin mejorar el rendimiento.
Optimización de Arquitectura Neural
Profundidad vs. Rendimiento
| Configuración | Parámetros | F1-Score | Memoria (MB) |
|---|---|---|---|
| 1 capa (64) | 38,465 | 0.9159 | 0.15 |
| 2 capas (128→64) | 85,569 | 0.9200 | 0.33 |
| 3 capas (128→64→32) | 93,857 | 0.9182 | 0.36 |
| 5 capas (256→128→64→32→16) | 210,289 | 0.9167 | 0.81 |
Análisis de Tamaño de Batch
16
F1: 0.916864
F1: 0.9200128
F1: 0.9187
Balance óptimo: Un batch size de 64 proporciona el
mejor equilibrio entre convergencia estable y utilización eficiente de
memoria, con un tiempo de procesamiento 42% menor que con batch size=16.
Hallazgo clave: El principio de parsimonia se confirma en este
dominio - arquitecturas más profundas (>2 capas) no mejoran el rendimiento pero
aumentan significativamente la complejidad computacional. La combinación de 2
capas (128→64) con batch size=64 proporciona el punto óptimo de eficiencia y
precisión.
Impacto de Técnicas de Regularización
Comparación de Técnicas
| Técnica | Precisión Test | Diff. Train-Test |
|---|---|---|
| Sin regularización | 0.9232 | 0.0124 |
| Dropout (0.2) | 0.9207 | 0.0095 |
| L2 (λ=0.01) | 0.9215 | 0.0087 |
| BatchNorm | 0.9193 | 0.0142 |
| L2+Dropout+BatchNorm | 0.9085 | 0.0052 |
Visualización de Sobreajuste
Precisión de Entrenamiento vs Prueba
Sin regularización
Train: 97%
Test: 92%
Con regularización combinada
Train: 91%
Test: 91%
Hallazgo contraintuitivo: A diferencia de lo esperado en redes
profundas, las técnicas de regularización agresivas reducen el rendimiento. Esto sugiere
que el modelo no está sobreajustado, sino que la complejidad inherente del dominio
requiere la capacidad expresiva completa de la red.
Insight: Para este caso específico, la selección efectiva de características
durante la fase de preprocesamiento y el uso de early stopping (paciencia=5) proporcionan
suficiente regularización implícita. Aplicar capas adicionales de regularización explícita
(Dropout, L2) solo degrada el rendimiento al limitar innecesariamente la capacidad expresiva del
modelo.