Instalación
- Instalar el motor de base de datos
- Instalar SQL Developer para gestionar la base de datos
Bases de Datos Relacionales
- Interrelaciones entre tablas (a través de columnas de referencia)
- Creación de usuario y carga de tablas
- Búsqueda de información que satisface los requerimientos
Guía Práctica
-
Crear los usuarios en SYSEstablecer permisos y roles adecuados
-
Crear la conexión del usuarioConfigurar los parámetros de conexión
-
Cargar la base de datosEn el usuario recién creado
-
Leer el caso y separar información
- Variables a ocupar en crudo (sin embellecedores)
- Variables no Variables (resultados de operaciones, porcentajes, etc.)
-
Embellecer el informeFormato adecuado para presentación
Sintaxis SQL
SELECT * | { [ DISTINCT ] columna expresión [alias],...}
FROM tabla
[WHERE condición]
[ORDER BY {columna, alias, expresión, posición_numérica} [ASC|DESC]];Operadores
| Operador | Descripción | Ejemplo |
|---|---|---|
| = | Igual a | salary = 5000 |
| !=, <> | Diferente a | department_id != 10 |
| <, > | Menor que, Mayor que | salary > 3000 |
| <=, >= | Menor o igual, Mayor o igual | hire_date <= '01-JAN-2010' |
| BETWEEN | Entre un rango (inclusivo) | salary BETWEEN 3000 AND 5000 |
| IN | En una lista de valores | department_id IN (10, 20, 30) |
| LIKE | Coincide con patrón | last_name LIKE 'S%' |
| IS NULL | Es nulo | commission_pct IS NULL |
Alias
De columna: as "alias"
SELECT employee_id AS "IDENTIFICACION EMPLEADO",
first_name || ' ' || last_name AS "NOMBRE DEL EMPLEADO",
salary salario
FROM employees;De tabla: from, join
SELECT e.employee_id, e.last_name, d.department_name
FROM employees e, departments d
WHERE e.department_id = d.department_id;Concatenación
SELECT employee_id "IDENTIFICACION EMPLEADO",
first_name || ' ' || last_name "NOMBRE DEL EMPLEADO",
salary salario
FROM employees;|| se utiliza para concatenar cadenas de texto en Oracle. En otros sistemas como SQL Server, se utiliza el operador +.
Order By
La cláusula ORDER BY va al final de la sentencia SELECT y permite ordenar en forma Ascendente (defecto) o Descendente.
SELECT employee_id, last_name, salary
FROM employees
ORDER BY salary DESC;Where
La cláusula WHERE restringe a que las filas deben cumplir con una condición para ser visualizadas, actualizadas o eliminadas.
- Se pueden comparar valores entre columnas, valor literal, expresiones aritméticas o funciones
- Se utilizan condiciones para filtrar
- Los valores de una columna son comparados fila a fila contra una condición
Elementos que se pueden comparar:
- Columna
- Constante
- Lista de valores
- Cadena de Caracteres
- Fechas literales
- Expresiones matemáticas
SELECT employee_id, last_name, salary
FROM employees
WHERE department_id = 90
AND salary > 10000;Operadores Lógicos
| Operador | Descripción | Ejemplo |
|---|---|---|
| AND | Todas las condiciones deben ser verdaderas | salary > 3000 AND department_id = 50 |
| OR | Al menos una condición debe ser verdadera | department_id = 60 OR job_id = 'IT_PROG' |
| NOT | Niega una condición | NOT (salary BETWEEN 1000 AND 2000) |
Variables de Sustitución &
SELECT last_name, department_id, salary*12
FROM employees
WHERE job_id = '&job_title';Cuando se quiere que el dato colocado se ocupe en dos lados, se pone en la primera variable && y en las demás &:
SELECT employee_id, last_name, job_id, &&column_name
FROM employees
ORDER BY &column_name;Creación de tabla nueva
Para crear nuevas tablas en la base de datos y guardar los datos de una consulta:
CREATE TABLE nombre_tabla [(columna, columna...)] AS
sentencia_select;Funciones
Una función siempre devuelve algo. Toma algo, lo procesa y devuelve algo nuevo. Cada función tiene por lo menos 1 parámetro.
Una dentro de otra, recordar el tipo de datos puede tener problemas con algunas funciones.
F3(F2(F1(col, arg1), arg2), arg3)
lower()- todo en minúsculaupper()- todo en mayúsculainitcap()- solo la primera en mayúsculasubstr()- corta (ej:SUBSTR(last_name, -2, 2))replace()- reemplaza (ej:REPLACE(last_name, 'A', 'Hola'))instr()- devuelve posiciónlength()- largo de textoconcat()o||- concatenatrim()- elimina espacioslpad()/rpad()- rellena izquierda/derecha
round()- redondeatrunc()- truncamod()- módulo
sysdate- fecha actualmonths_between()- meses entre fechasadd_months()- sumar/restar meseslast_day()- último día del mesextract()- extrae parte de fecha
Funciones de conversión
| Función | Descripción | Ejemplo |
|---|---|---|
TO_NUMBER |
Convierte a número | TO_NUMBER('1234,56') |
TO_CHAR |
Convierte a texto | TO_CHAR(salary, '$999G999') |
TO_DATE |
Convierte a fecha | TO_DATE('2007/05/31','YYYY/MM/DD') |
Manejo de nulos
-- NVL: Reemplaza NULL por un valor
NVL(manager_id, 0)
-- NVL2: Distintos valores si es NULL o no
NVL2(commission_pct, 'si no es null', 'si es null')
-- NULLIF: Retorna NULL si los dos valores son iguales
NULLIF(x, y)
-- COALESCE: Devuelve el primer valor no nulo
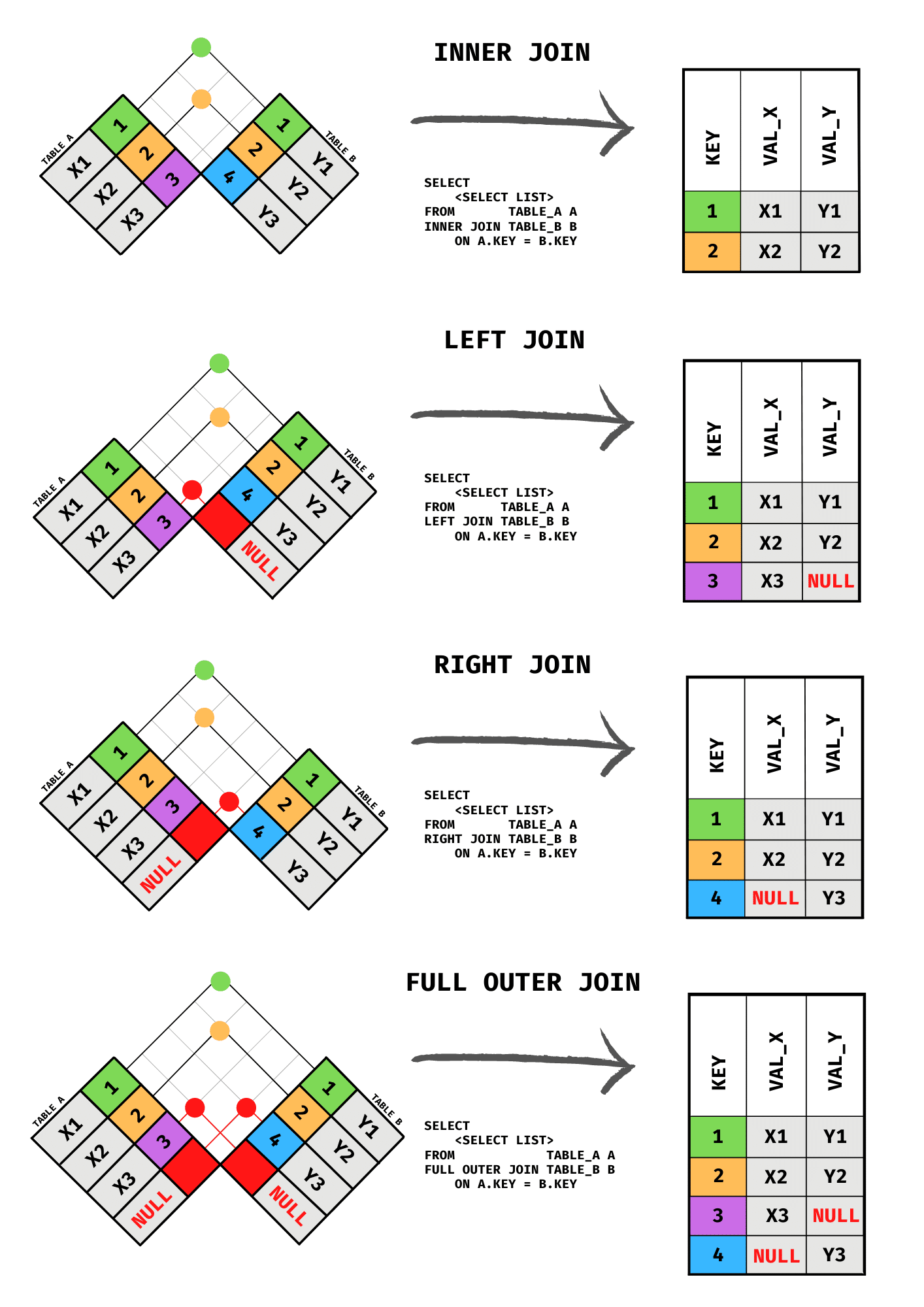
COALESCE(expr1, expr2, …, exprn)Joins
Inner Join
Muestra solo lo que tienen en común ambas tablas.
SELECT suppliers.supplier_id, suppliers.supplier_name,
orders.order_date
FROM suppliers
INNER JOIN orders
ON suppliers.supplier_id = orders.supplier_id;Left Outer Join
Muestra todo lo que tiene la tabla de la izquierda.
SELECT suppliers.supplier_id, suppliers.supplier_name,
orders.order_date
FROM suppliers
LEFT OUTER JOIN orders
ON suppliers.supplier_id = orders.supplier_id;Right Outer Join
Muestra todo lo que tiene la tabla de la derecha.
SELECT orders.order_id, orders.order_date,
suppliers.supplier_name
FROM suppliers
RIGHT OUTER JOIN orders
ON suppliers.supplier_id = orders.supplier_id;
Subconsultas
- Consulta que solo da una celda (un dato) sirve para el WHERE o comparar datos
- Consulta que da una columna de datos sirve para IN() o cualquier cosa que pida más de un dato
-- Subconsulta que devuelve un solo valor
SELECT employee_id, last_name, job_id, salary
FROM employees
WHERE salary > (SELECT AVG(salary) FROM employees);
-- Subconsulta que devuelve múltiples valores
SELECT employee_id, last_name
FROM employees
WHERE department_id IN (SELECT department_id
FROM departments
WHERE location_id = 1700);Operadores Set
Junta dos tablas con los mismos datos y no se duplican.
SELECT employee_id, job_id FROM employees
UNION
SELECT employee_id, job_id FROM job_history;Junta dos tablas con los mismos datos (incluye duplicados).
SELECT employee_id, job_id FROM employees
UNION ALL
SELECT employee_id, job_id FROM job_history;Muestra solo los datos comunes en ambas tablas.
SELECT employee_id, job_id FROM employees
INTERSECT
SELECT employee_id, job_id FROM job_history;A le quita lo que coincide con B.
SELECT employee_id, job_id FROM employees
MINUS
SELECT employee_id, job_id FROM job_history;Sentencias DML
INSERT
Inserta datos en una tabla.
INSERT INTO employees (employee_id, first_name, last_name, email, hire_date, job_id)
VALUES (207, 'John', 'Smith', 'JSMITH', SYSDATE, 'IT_PROG');UPDATE
Actualiza los datos de una tabla.
UPDATE employees
SET salary = salary * 1.10
WHERE department_id = 90;DELETE
Borra datos de una tabla.
DELETE FROM employees
WHERE department_id = 20;TRUNCATE
Borra todos los datos de una tabla.
TRUNCATE TABLE job_history;Control de transacciones
COMMIT: Confirma acciones y guarda datos en las tablas.
ROLLBACK: Deshace acciones ya aplicadas hasta el último commit.
Privilegios
Privilegios de sistema (SYS)
Permisos de creación, grant, permisos para los usuarios.
-- Otorgar privilegios de sistema
GRANT CREATE SESSION TO usuario;
GRANT CREATE TABLE TO usuario;
GRANT CREATE VIEW TO usuario;Privilegios de objetos (TABLAS)
Permisos para tablas, ON.
-- Otorgar privilegios de objeto
GRANT SELECT, INSERT, UPDATE ON employees TO usuario;
GRANT SELECT ON departments TO PUBLIC;
REVOKE DELETE ON employees FROM usuario;Usuarios
- Crea las tablas
- Tiene todos los permisos
- Da permisos a otros usuarios
- Tiene el rol "resource"
GRANT RESOURCE TO C##DUEÑO;- Tiene algunos permisos que le da el dueño
- Puede tener permisos específicos
- Generalmente puede modificar datos
GRANT SELECT, INSERT, UPDATE ON employees TO C##DESARROLLADOR;- Solo lee la información
- No puede realizar ninguna acción de modificación
- Tiene permisos de consulta únicamente
GRANT SELECT ON employees TO C##CONSUMIDOR;Los nombres de usuario en versiones recientes de Oracle deben ir precedidos de C## cuando se utiliza el modo de contenedor múltiple (CDB).
Vistas
Las vistas guardan las consultas en un paquete para poder volver a ver los informes de manera más automática. El usuario requiere permisos específicos para crearlas.
-- Crear una vista simple
CREATE VIEW emp_dept_view AS
SELECT e.employee_id, e.first_name, e.last_name,
d.department_name
FROM employees e JOIN departments d
ON e.department_id = d.department_id;
-- Usar la vista
SELECT * FROM emp_dept_view
WHERE department_name = 'IT';Secuencias
Secuencia de números que se le pueden ajustar varios parámetros como el número inicial, de a cuánto avanza, si es cíclica, autoincrementar, etc. Se puede concatenar con columnas.
-- Crear una secuencia
CREATE SEQUENCE employees_seq
START WITH 207
INCREMENT BY 1
NOCACHE
NOCYCLE;
-- Usar una secuencia
INSERT INTO employees (employee_id, first_name, last_name, email, hire_date, job_id)
VALUES (employees_seq.NEXTVAL, 'Jane', 'Doe', 'JDOE', SYSDATE, 'IT_PROG');
-- Obtener el valor actual
SELECT employees_seq.CURRVAL FROM dual;Índices
Los índices optimizan queries y mejoran el rendimiento. Solemos ocupar dos tipos: los B-tree y los de PK de las columnas.
Creación de índice
-- Índice simple
CREATE INDEX emp_last_name_idx
ON employees (last_name);
-- Índice compuesto
CREATE INDEX emp_dept_job_idx
ON employees (department_id, job_id);Creación de índice único
-- Índice único
CREATE UNIQUE INDEX emp_email_idx
ON employees (email);
-- Eliminar un índice
DROP
INDEX emp_last_name_idx;Los índices mejoran la velocidad de las consultas, pero agregan sobrecarga en operaciones de inserción, actualización y eliminación. Utiliza índices en columnas que se usan frecuentemente en cláusulas WHERE, JOIN o ORDER BY.
Recursos Adicionales
Orden de Ejecución SQL
En SQL, las consultas se procesan en un orden específico que es importante entender para escribir consultas efectivas:

Orden lógico de procesamiento SQL

Jerarquía de operaciones SQL

Diagramas de JOINs en SQL
Orden real de ejecución:
- FROM / JOIN - Determina las tablas de datos y las combina según sea necesario
- WHERE - Filtra las filas según condiciones
- GROUP BY - Agrupa filas que comparten valores
- HAVING - Filtra grupos según condiciones
- SELECT - Selecciona las columnas específicas
- DISTINCT - Elimina filas duplicadas
- ORDER BY - Ordena el conjunto de resultados
- LIMIT / OFFSET - Limita el número de filas devueltas
Orden de Ejecución SQL
En SQL, las consultas se procesan en un orden específico que es importante entender para escribir consultas efectivas:
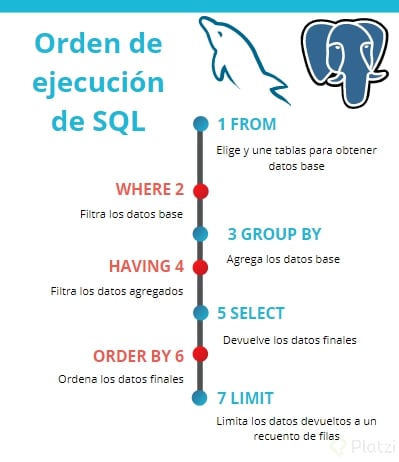
Orden lógico de procesamiento SQL

Jerarquía de operaciones SQL

Diagramas de JOINs en SQL
Orden real de ejecución:
- FROM / JOIN - Determina las tablas de datos y las combina según sea necesario
- WHERE - Filtra las filas según condiciones
- GROUP BY - Agrupa filas que comparten valores
- HAVING - Filtra grupos según condiciones
- SELECT - Selecciona las columnas específicas
- DISTINCT - Elimina filas duplicadas
- ORDER BY - Ordena el conjunto de resultados
- LIMIT / OFFSET - Limita el número de filas devueltas
Cómo se procesan las subconsultas
Las subconsultas se ejecutan desde la más interna hacia la más externa:
SELECT employee_id, last_name
FROM employees
WHERE department_id IN (
SELECT department_id
FROM departments
WHERE location_id = (
SELECT location_id
FROM locations
WHERE city = 'Toronto'
)
);- Primero se ejecuta:
SELECT location_id FROM locations WHERE city = 'Toronto' - Luego:
SELECT department_id FROM departments WHERE location_id = resultado_anterior - Finalmente:
SELECT employee_id, last_name FROM employees WHERE department_id IN resultado_anterior
Proceso de ejecución de subconsultas
Consejos Finales
Recomendaciones
- Utiliza alias descriptivos para las tablas y columnas
- Comenta tu código SQL para facilitar la comprensión
- Sé específico en las columnas que necesitas (evita SELECT *)
- Utiliza parámetros de enlace en lugar de concatenar cadenas
- Optimiza consultas complejas con índices adecuados
- Realiza pruebas con conjuntos de datos pequeños antes de ejecutar en producción
Errores comunes a evitar
- No verificar la sintaxis antes de ejecutar
- Olvidar condiciones en cláusulas WHERE (afecta a todas las filas)
- No hacer COMMIT después de operaciones DML
- Crear consultas excesivamente complejas y difíciles de mantener
- No considerar el rendimiento en tablas grandes
- Ignorar la posibilidad de valores NULL